机器学习的并行策略
机器学习中的分布式的并行优化
简介
机器学习的并行计算指的是对机器学习过程中遇到的计算问题采用并行计算的方式进行合适的加速,缩短训练所需的时间。此处所指的时间既指物理时间,也指CPU时间或者GPU时间。
和其他大数据计算问题类似,有两种途径来实现对计算的并行加速,一种是向单一机器添加更多计算资源,可以称之为纵向扩展,另外一种是类似分布式系统一样,在系统中添加更多的节点,节点可能是CPU,GPU甚至是单机环境等等,可以称之为横向扩展。
纵向扩展
CPU或者GPU时间的缩短主要应用纵向扩展,通过对特定问题设计特定的CPU或者GPU模块及指令集等,通过硬件加速机器学习算法中的特定问题。虽然机器学习近年来涌现出各种各样互不相同的算法,但是对于底层的计算而言,这些算法所使用的数据操作的本质基本相似,都是线性代数中的基本操作,是对向量,矩阵,张量的基本计算,因此涌现出了很多种加速方法和实现方案。
主要策略
纵向扩展中的常用方法是,添加可编程GPU。最初,GPU用于机器学习的应用受到限制,因为GPU使用纯SIMD(单指令多数据)模型,不允许内核执行不同的代码分支;所有线程都必须执行完全相同的程序。
-
后来出现的通用GPU,即可以执行任意代码的GPU。这些产品可以作为加速器添加到传统机器上,加快了机器学习的训练效率。例如Nvidia的Titan V和Tesla V100显卡就可以显著加速机器学习的学习和训练。
-
除了使用通用GPU加速之外,还可以使用专用集成电路(ASIC)来加速机器学习,专用集成电路主要通过高度优化的设计实现特定功能。
-
在最近几代产品中,即使是通用CPU也增加了向量指令的可用性和宽度,以加速计算密集型问题(如机器学习算法)的处理。这些指令是矢量指令,是AVX-512系列的一部分,具有增强的字变量精度并支持单精度浮点运算。
横向扩展
采用纵向扩展的优化方法之外,还可以对单一问题进行拆解,使其可以在多处理器,多显卡,多机的环境下进行计算,主要解决单处理器,单显卡,单机性能提升较慢,难以跟上深度学习中计算资源的需求问题,通过数量来加速计算。在工程实践中采用横向扩展的案例也并不少见。
- 采用横向扩展,单机设备的成本较低,同时易于增加算力。
- 单机设备在计算过程中发生故障时往往难以恢复,对于多机环境而言,单个处理器发生故障时,系统仍然可以通过启动部分恢复(例如,基于通信驱动的检查点1或部分重新计算2)继续运行。
- 单处理器环境下,对于大规模数据的读取可能有IO瓶颈。
- 横向扩展的一个主要挑战是,并非所有ML算法都适用于分布式计算模型。
数据并行和模型并行
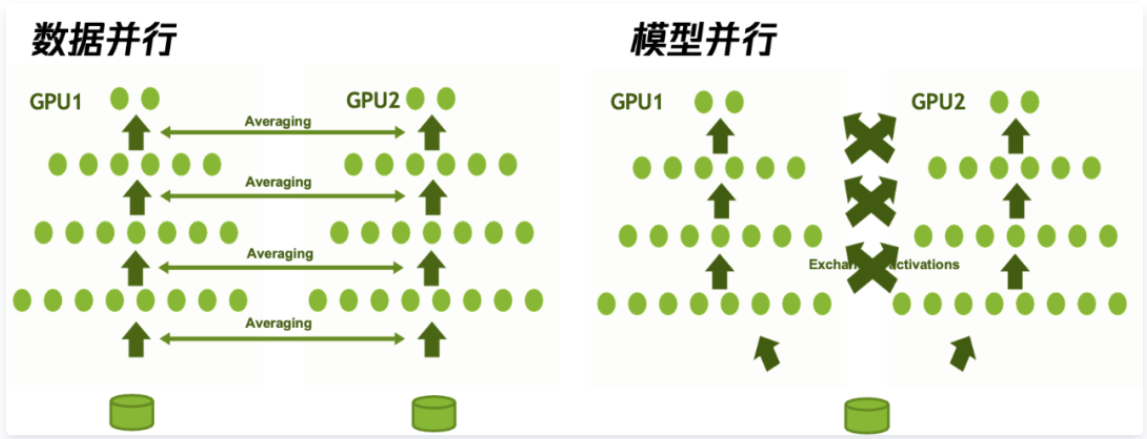
- 数据并行将原始数据分配到不同的工作节点上并行训练。其中,每一个工作节点使用不同的部分数据,但是都拥有完整的模型,工作节点之间一般会同步自己的局部梯度信息,再进行汇总,得到整体的更新结果。数据并行依赖于优化算法的选择。
- 模型并行一般是由于模型太大,单机无法储存,将模型的不同部分放在不同的节点上进行训练,常用的方式是每一个节点均使用相同的数据,但是只使用模型的一部分来进行。因此模型并行依赖于模型的设计。
在实际应用过程中,数据并行更为常见。
主要策略
横向扩展组成的分布式机器学习系统中,性能主要取决于三部分,计算瓶颈,IO瓶颈和通信瓶颈。
由于IO和通信的限制,虽然机器数量在不断增加,但加速效果并不是线性提升,在增加数量过程中,会产生性能损耗,比如,增加了十倍的机器,理想训练速度能够增加十倍,实际上往往却只增加了一两倍,性价比很低。这实际上是因为IO和通信瓶颈所导致的。
期望能够提高加速比,使得分布式机器学习可以更快,就需要降低通信和IO时间开销的同时,加快计算性能,才能提升计算的时间占比,使得性能损耗更小。
下面从这三个点来展开横向扩展的优化策略。
通信优化
通信上,一方面提升通信速度,比如通信拓扑的改进,通信步调和频率的优化,另一方面也可以减少通信内容和次数,比如梯度压缩和梯度融合技术等。
通信方式
- Share memory:同的处理器共享一块内存,没办法同时用很多处理器进行工作
- Message passing:有多个节点,节点的处理器之间是可以采用共享内存,节点之间不能共享内存。节点之间可以网线相连接也可以使用 TCP/IP 进行消息传递。需要注意的是,采用Message passing方法时通常使用MPI的标准库来进行并行通信。根据节点的协调方式可以分为两类
- 点对点(point-to-point)通信,这是高性能计算(HPC)中最常使用的模式,通常是与其最近的邻居进行通信,每个实例都是单发送方,单接收方
- 集合(collective)通信,也可以叫做C/S架构,存在多个发送方和接收方。
通信步调
- Bulk Synchronous Parallel(BSP) 是最简单的模型,其中程序通过同步每个计算和通信阶段来确保一致性。遵循BSP模型的程序示例是MapReduce。优点是ML程序可以保证输出正确的解决方案。缺点是,完成的节点必须在每个同步障碍处等待,直到所有节点完成,这会导致在某些节点进度比其他工作人员慢的情况下产生开销。
- Stale Synchronous Parallel(SSP)通过允许速度更快的节点向前移动一定数量的迭代来缓解同步开销。如果超过此数字,则暂停所有工作进程。节点在缓存的数据版本上操作,并且仅在任务周期结束时提交更改,这可能会导致其他节点在过时的数据版本上操作。数据SSP的主要优点是它仍然享有强大的模型收敛保证。然而,缺点是,当陈旧性变得太高时(例如,当大量机器减速时),收敛速度会迅速恶化。
- Approximate Synchronous Parallel(ASP)限制了参数的不准确程度。这与SSP形成对比,SSP限制了参数的过时程度。一个优点是,每当聚合的更新无关紧要时,服务器都可以延迟同步。一个缺点是,很难选择定义哪些更新重要,哪些更新不重要的参数。
- Barrierless Asynchronous Parallel /Total Asynchronous Parallel (BAP/TAP) 让节点并行通信,而无需彼此等待。其优点是通常可以获得尽可能高的加速比。一个缺点是,模型可能收敛缓慢,甚至发展不正确,因为与BSP和SSP不同,误差随延迟而增长。
MapReduce和Spark
MapReduce是C/S架构,Server可以把信息广播到worker节点。Server先定义一个 Map 操作,这个 Map 操作是由worker节点完成,然后worker把结果传回client并处理,这个叫做reduce。梯度下降可以用 MapReduce 进行并行化。并行化的过程中,数据被分给 worker 进行计算。每一个梯度下降过程包含一个广播、map和一个 reduce 操作。
MapReduce的主要问题有两个,一是原语的语义过于低级,直接使用其来写复杂算法,开发量比较大;另一个问题是依赖于磁盘进行数据传递,性能跟不上业务需求。
为了解决MapReduce的两个问题,Matei在3中提出了一种新的数据结构RDD,并构建了Spark框架。Spark框架在MR语义之上封装了DAG调度器,极大降低了算法使用的门槛。
- Spark是基于内存进行数据处理的,MapReduce是基于磁盘进行数据处理的。
- DAG计算模型在迭代计算上还是比MapReduce的效率更高。
- MapReduce中,reduce任务需要等待所有map任务完成后才可以开始;在Spark中,分区相同的转换构成流水线放到同一个任务中运行。
较长时间内spark几乎可以说是大规模机器学习的代表,直至后来李沐完善了参数服务器,开拓了大规模机器学习的领域以后,spark才暴露出一点点不足。
参数服务器
参数服务器的概念最早大概可以追溯到Alex Smola于2010年提出的并行LDA的框架,其采用一个分布式的Memcached作为存放参数的存储,用于在分布式系统不同的Worker节点之间同步模型参数,而每个Worker只需要保存它计算时所依赖的一小部分参数。
在此之后,PS又有了很多改进,其中又以李沐2014年提出的ps-lite4(所谓第三代PS架构)为主要代表,也进一步加快了业界广泛使用参数服务器的步伐,在广告,推荐等各领域内大放异彩,时至今日,依然在各大公司内发挥着重要作用。
ps-lite的主要架构示意图如下图所示。
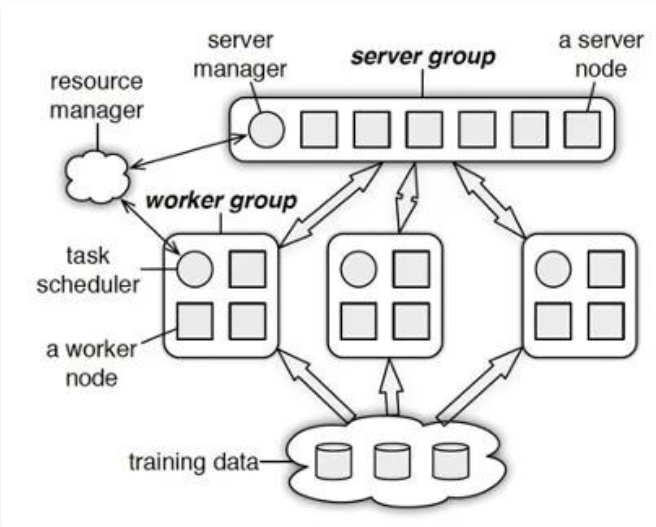
Paraeter Server框架中,每个server都只负责分到的部分参数(server共同维持一个全局共享参数)。server节点可以和其他server节点通信,每个server负责自己分到的参数,server group 共同维持所有参数的更新。server manage node负责维护一些元数据的一致性,例如各个节点的状态,参数的分配情况。worker节点之间没有通信,只和对应的server有通信。
每个worker group有一个task scheduler,负责向worker分配任务。一个具体任务运行的时候,task schedule负责通知每个worker加载自己对应的数据,然后去server node上拉取一个要更新的参数分片,用本地数据样本计算参数分片对应的变化量,然后同步给server node;server node在收到本机负责的参数分片对应的所有worker的更新后,对参数分片做一次update。
从通信视角上看,其是一种比较朴素直观的算法过程,可以看成是reduce+broadcast的过程,先是将worker上的信息reduce到server节点上,之后server节点汇总了信息后,再broadcast到worker节点上去,完成了一次信息的处理过程,如下图所示。在这个结构中也能看到,worker之间不通信,而全部依赖于server节点,worker之间的通信能力未得到充分利用, 并且是单工通信,没有同时利用上行带宽和下行带宽,当参数非常稠密,需要通信的信息比较多时,server节点有可能成为瓶颈。
但是如果参数是高维稀疏,单机无法保存全部参数,且每个worker无需访问全部的参数的情况,如推荐中的百亿级feature的LR,LDA,小数据量的通信延迟较低,加上PS架构支持异步更新,可以减少阻塞,加快训练速度。粗略地说,原始的PS架构更适合稀疏超大模型,且更容易容灾,也因此在推荐领域内广泛应用。
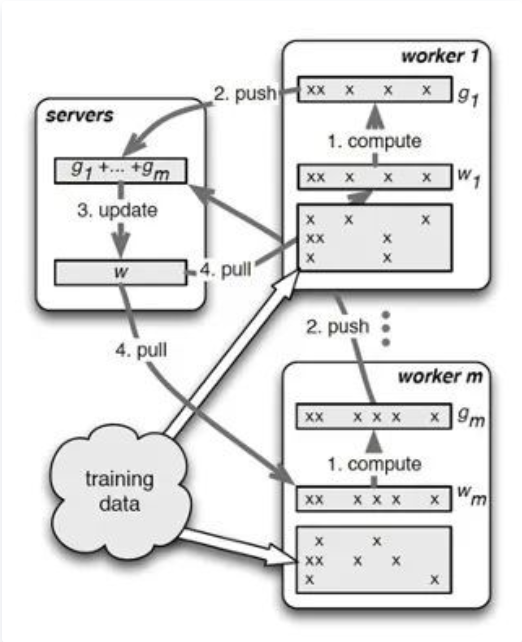
Ring All-Reduce
PS架构虽然在很多领域内大放异彩,应用广泛,但是当模型稠密,需要大量交换信息的情况下,Server节点很容易成为瓶颈,限制了其作用,也因此有了将Ring AllReduce这一类通信方法应用到机器学习领域的尝试。
实际上,Ring AllReduce算法在高性能计算领域中已经有了比较长的历史,OpenMPI中至少在2007年就有了关于其的开源实现。然而机器学习领域内的对此知之甚少,更加不知道怎么利用其来加速分布式机器学习的速度。直到2016年,百度的研究人员首次尝试将Ring AllReduce算法应用到深度学习领域内,并在很多问题上取得了明显比PS架构更显著的加速效果,在深度学习领域取得了广泛的关注。
正如名字中所表达,**Ring AllReduce算法首先需要将集群内各个节点按照环状的形式排列,在这个环中,每一个节点都只接收其左邻居节点的信息,且都只发送信息给自己的右邻居节点。**在具体的通信内容和方式的组织上,大概可以分为两部分,第一部分,对于N个节点的集群,将每个节点上数据切分为N份,然后经过N-1轮的Reduce-Scatter过程。具体地,每一轮中,每个GPU将自己的一个chunk发给右邻居,并接收左邻居发来的chunk,并累加,经过这样的步骤,每一个节点都拥有一部分数据的最终结果。第二部分,与上部分相类似,进行N-1轮的AllGather过程,将每一个节点上的一部分的完整信息传递到所有节点上,经过此步骤,每一个节点上就拥有了所有数据的完整信息。
减少通信内容–梯度压缩
梯度压缩里有两大类主要的方案,一是梯度量化的方法,二是梯度稀疏化的方法。
梯度量化
模型量化等技术在模型推理上发展的相对成熟,也已经有很多成功的应用,可以有效的减少模型尺寸,降低模型推理成本。然而,在训练中,目前还不能做到直接用很小的或是量化的模型进行训练,其往往会导致训练的效果变差,达不到预期的效果。因此一些研究人员从梯度着手,期望能够在不改变模型本身大小和性能的情况下,降低梯度通信的时间。默认情况下,梯度是用32比特的浮点数来表示,梯度量化就是用更低的精度来表示梯度的方式降低梯度通信的开销。
- 基于误差补偿机制的1-bit SGD是梯度量化领域内比较有代表性的工作,其是由微软亚研院的研究人员们在2014年发表的。
- 1-bit SGD的思路也比较简单,就是直接用1-bit来表示传统的梯度,且直接用0来作为量化的阈值
- 可以认为其只保留了梯度中的方向信息,而减少了梯度的具体数值信息,再使用一般的SGD方法来进行优化。
- 当然,为了减少梯度损失的影响,他们也引入了两个技巧,一是使用误差补偿机制,以减少梯度误差逐渐放大,二是在训练初期,仍然使用完整的浮点精度的SGD来进行预训练,再之后才转用1-bit SGD进行训练,以使得训练更加稳定。
- 在1-bit SGD后,又有了Terngrad量化的方法。
- 相对于1-bit SGD,其主要区别是会将梯度量化为-1,0,+1三个值,并且通过加入随机的二元向量的方式引入更多的随机性。
- 除此之外,其会对每一层layer的梯度做三元化处理和梯度裁剪方法。实际过程中,对每一层采用不同的缩放因子,同时区分权重和偏置。经过上述处理后,Terngrad量化在一些问题上的精度下降已经很少,甚至没有损失,但是其通信开销得到了16+倍的提升。
梯度稀疏化
除了梯度量化外,另一类梯度压缩的方法就是梯度稀疏化,其主要思想就是在通信时只通信少部分重要的(大的)梯度,而其他的则不通信,累加到下一个迭代中去。
- Gradient Dropping是梯度稀疏化领域中的一个代表性工作,其主要做法是**通过设定梯度丢弃的比例Drop ratio,再通过计算找到满足需要丢弃的梯度的阈值Threshold,来对梯度进行稀疏化,未通信的梯度会累加到下一次迭代。**Drop ratio的选择方面,他们比较了90%, 99%, 99.9%的区别,99.9%的情况下,loss曲线还是呈现下降趋势,但是会收敛到一个比较差的结果,而99%的drop比重不会带来太大的影响,通信数据降低了50倍。另外,通过layer normalize(层归一化)的方法,把每层的参数归一化到一个范围,然后选取drop比重,从而确定阈值,这样对每层网络都可以保留原始的泛化能力,从而有利于收敛性。
- Deep Gradient Compression则进一步地通过各项技巧来降低了梯度稀疏化后的精度损失。相对于Gradient Dropping而言,其增加了Momentum Correction, Local Gradient Clipping, Momentum actor Masking,以及Warm-up Training等技术。通过这些技术,进一步地降低了精度损失,在不少数据集上都达到甚至超过了原始baseline的表现。
IO优化
IO上,通过代码优化,减少IO的阻塞,尽量使得IO与计算可以overlap。计算上,一方面,可以进一步地优化单机的计算性能,比如图/OP优化,编译器优化等,另一方面,分布式带来了大batch size上的优化问题,又需要解决。
机器学习系统中,通常需要先加载处理样本,再利用样本进行训练,当样本不够时,会阻塞等待,batch size变大时,其阻塞时间也会变长,更进一步地,多leaner分布式训练时,同步训练的整体进度会由最慢的learner决定(木桶效应)。这就使得,如果IO上优化的不好,就会导致大量的昂贵GPU资源空载,算力没有被充分利用,其利用率可能会偶尔到很高,而很多时候在很低的水平。
监督学习的IO优化
针对IO方面的优化,对于监督学习而言,目前已有一系列的处理方案,比如通过数据预取和缓存prefetch,比如通过并行处理的方式(num_parallel_calls),以及尽量使tf.record,tf.data减少sess.run, placeholders的方式来优化IO,使得计算与IO可以尽量多地overlap,以提升算力的应用。
强化学习平台Avatar上的部分IO优化
与监督学习不同的是,强化学习中的样本需要主动地通过交互而来,这也就带来了更多更复杂的IO问题。Avatar就是一个公司内开源的大规模分布式强化学习平台,其已经可以支持包括MOBA,FPS,动作格斗,竞速等各种品类的游戏AI的研发,其在IO优化上也做了很多的工作,这里简单阐述其中的部分内容。
- 一是通过大量的处理来优化内存,包括通过snapp快速压缩解压样本,通过bytesarray预先分配buff池,通过memoryview避免内存拷贝,利用tcmalloc优化python内存管理等。
- 二是对于大量的计算逻辑进行优化,以降低样本处理的时间,对样本处理相关模块进行重构,向量化处理并且从trainer中解耦,利用Connectors多进程多cpu优势并行处理。
- 三是自定义ZMQ Op,包括C++实现ZmqConnectionHandleOp和ZmqPullOp,注册&编译成.so,Python实现ZmqPullSocket包装类加载so并暴露pull接口(返回op)供python侧构建tf graph。
- 四是TF多线程、多核调度ZMQ Op,包括TF QueueRunner和TF Coordinator用多线程来衔接zmq_op和后续其他依赖op,并发拉取数据,以及Trainer预处理剩余逻辑全部使用tf op来并行处理。
- 五是自定义实现Replay Buffer,进一步地满足数据预取功能和算法上的其他需求。通过上述处理后,Avatar上的IO和计算可以实现更多的重叠,训练速度变得更快。同时,Leaner(GPU)的资源利用率得到了极大的上升,能够达到90%以上。
计算优化
利用分布式机器学习训练模型,算法层面上的一个主要区别是,多个节点并行会使得实际的batch size变大,比如单机的batch size是B,则N卡同时计算的batch size就变成了N∗B,随着batch size变大,其训练速度会逐渐变快,其中的一个原因是,大batch size减少了通信和IO的时间和次数,计算的时间占比会增加,且减少了迭代次数。
然而,当我们真的直接去利用分布式来加速训练时,不幸的发现,随着batch size的增大,训练出现了明显的精度降低,其中一个可能的原因是,大的batch size会带来泛化性变差的问题,这可能主要是由Sharp Minimum导致的(局部最优点)。小batch size训练时,其对应的曲线更接近于Flat Minimum的结构,而大batch size训练时,则更接近于Sharp Minimum的结构。假设我们训练时都得到了很好的结果,在Flat Minimum的结构下,训练集与测试集上的结果差异较小,而在Sharp Minimum下,则会有非常大差异。
训练参数的调整(优化器的改进)
- Learning Rate Linear Scaling的技术,其出发点是当batch size从B增加到kB时,在总的Epochs不变时,其总的迭代次数则会减少k倍,那么,在learning rate η不变的情况下,模型参数变化的幅度显然是要比之前少了很多的,因此提出了也将η乘以k来进行线性扩大,以提升训练速度。当然,在后续的一些工作中,也有在其他的优化器中采用例如平方根来进行放缩的方式。
- 采用了Warmup Rule的技术,其主要的出发点是在经过上述的学习率放大后,在初始训练时,非常容易出现不稳定的现象,导致最后很难收敛。因此,他们在刚开始训练时,仍然从比较小的η开始,再逐渐增大,训练了一定的Epochs以后,再按照上述的kη的方式进行训练。在此之后,也有一些工作在训练的后期逐渐降低学习率,被称之为learning rate decay
- 除了常用的SGD,BGD,AdaGrad,RMSProp,Adadelta,Adam之外,层数多时也有LARS,LAMB等优化器可以选择。
-
Elmootazbellah Nabil Elnozahy, Lorenzo Alvisi, Yi-Min Wang, and David B. Johnson. 2002. A survey of rollback-recovery protocols in message-passing systems. ACM Comput. Surv. 34, 3 (2002), 375–408 ↩︎
-
Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, and Ion Stoica. 2010. Spark: Cluster computing with working sets. In Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing (HotCloud’10) 10, 10–10 (2010), 95. ↩︎
-
Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,Scott Shenker, and Ion Stoica. 2012. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation. USENIX Association, 2–2 ↩︎
-
Li Mu, David G. Andersen, Jun Woo Park, Alexander J. Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J. Shekita, and Bor-Yiing Su. “Scaling distributed machine learning with the parameter server.” In 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14), pp. 583-598. 2014. ↩︎