IRNN
IRNN模型1
Novelty
- 专注于解决RNN模型中的梯度消失问题
- 使用单位矩阵来初始化RNN从而部分解决梯度消失和梯度爆炸问题
- 使用ReLU激活函数代替Sigmoid激活函数也用于解决梯度消失问题(要配合第二点,否则很有可能梯度爆炸)
问题和动机
- 梯度消失和梯度爆炸的问题导致RNN模型难以学习到远距离依赖
- 过去的解决方法依赖于复杂的优化技术和网络架构
- 提出一种较为简单的方式进行优化
过去的解决方法
虽然效果上有改进,但并不常用,原因可能如下
-
最成功的改进LSTM
虽然能解决长距离依赖,但本文作者认为此结构并不是最优的结构
Idea
- 使用ReLU(Rectified Linear Units)激活函数(解决梯度消失,但单纯使用ReLU,可能导致梯度爆炸)
- (trick)通过单位矩阵或者它的缩放版本来初始化RNN中的权重矩阵(可以缓解梯度爆炸和梯度消失)
作者认为以下工作与本文工作类似
实验
实验中发现了下述炼丹技巧
为LSTM设置更高的forget gate bias能更好的解决长距离依赖关系
参数应用高斯随机初始化时使用文献9的值时效果更好。
实验中IRNN中非递归权重使用均值为0,标准差为0.001的高斯分布来初始化。分别展示了IRNN,标准LSTM,使用tanh激活的RNN和使用ReLU激活的RNN在4个实验上的结果。
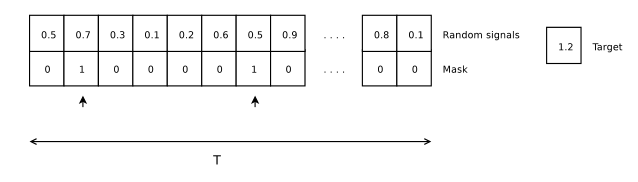
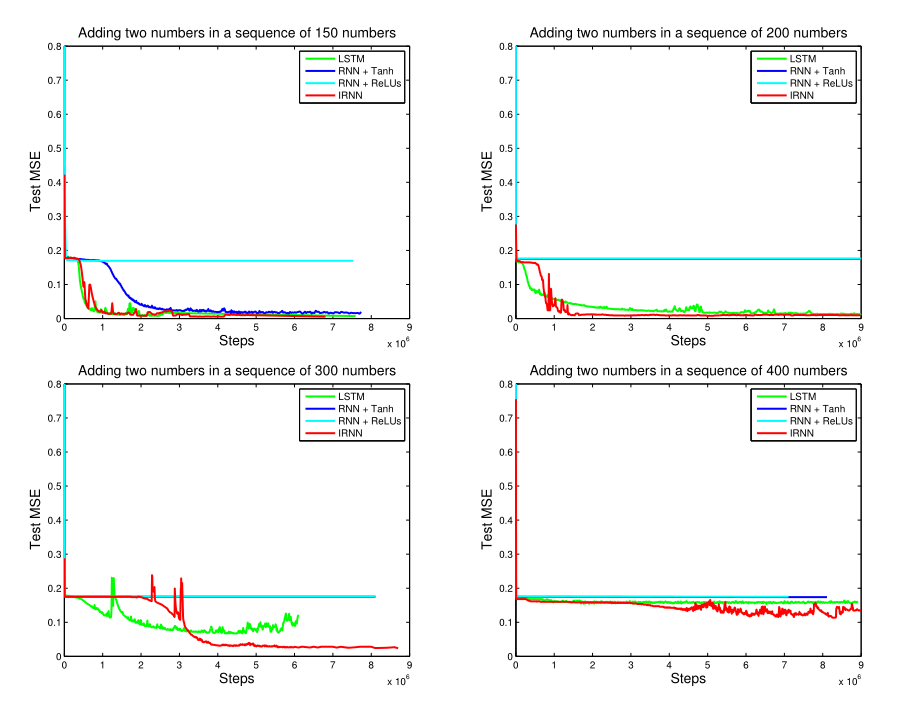
The Adding Problem实验
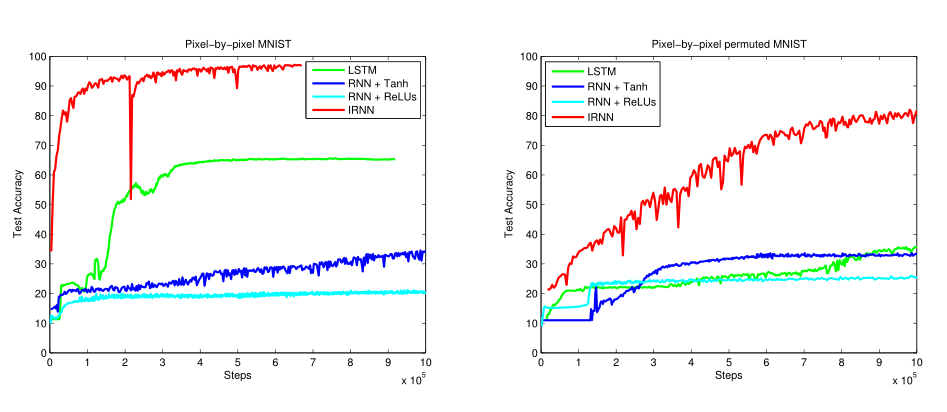
MNIST Classification from a Sequence of Pixels实验
实验通过将图片的784个像素顺序输入网络中,在完全学习完784个像素后,再进行图片的分类。一次每个网络的循环步长为784。除了对原始图片进行预测的实验之外,还对图片的像素进行固定的随机重新排列后进行了第二次实验。
Language Modeling实验

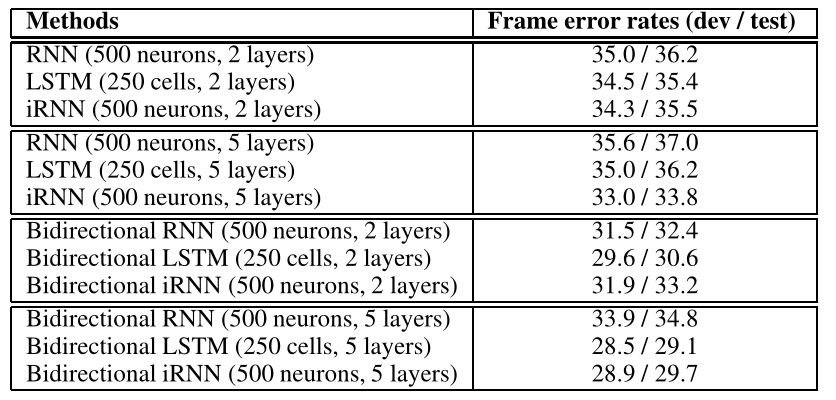
Speech Recognition实验
在该实验中作者发现使用单位矩阵初始化效果较差,本文猜测的原因如下
- 正常IRNN很难忘记过去的信息
- 难以专注当前的输入
我觉得等于没说,根据模型和结果猜原因
因此本文提出了补救办法,并认为其可以作为不需要长距离依赖时模型的补救办法
- 用一个小标量和单位矩阵的乘积来初始化(本文中使用的是0.01I)
论文Insight
- 使用单位矩阵初始化循环参数(可能缓解梯度爆炸的问题)
- 使用ReLU激活(可以缓解梯度消失的问题)
- 二者共同作用可使得RNN模型性能得到改善
- 在不需要长期依赖时,可以使用小标量与I的乘积来进行初始化,类似于LSTM中的遗忘门机制
思考中的问题
- 超参初始化问题,xariv,He,和本文中9提到的初始化的关系和效果
- 单位矩阵在模型中起到的作用(推导反向传播)
- 使用ReLU激活的RNN效果比tanh还差的原因(单纯使用ReLU会导致梯度爆炸,同时会导致输出值过大)
-
https://arxiv.org/abs/1504.00941 (A Simple Way to Initialize Recurrent Networks of Rectified Linear Units) ↩︎
-
Learning recurrent neural networks with Hessian-Free optimization. In ICML, 2011. ↩︎
-
Deep learning via Hessian-free optimization. In Proceedings of the 27th International Conference on Machine Learning, 2010. ↩︎
-
On the difficulty of training recurrent neural networks. ↩︎
-
On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, 2013. ↩︎
-
Learning longer memory in recurrent neural networks ↩︎
-
Parsing with compositional vector grammars ↩︎
-
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks ↩︎
-
Random Walk Initialization for Training Very Deep Feedforward Networks ↩︎ ↩︎