SCRN
Contents
SCRN模型1
Novelty
- 通过为RNN添加一个参数缓慢变化的隐藏层来捕获长距离依赖,公式如下所示
\begin{align*} s_t &= (1-\alpha)Bx_t + \alpha s_{t-1} \\ h_t &= \sigma(Ps_t+Ax_t+Rh_{t-1}) \\ y_t &= f(Uh_t+Vs_t) \end{align*}
- 约束该隐藏层中的B为对角矩阵,由于B为对角矩阵,且没有使用激活函数,所以该隐藏层的梯度流稳定

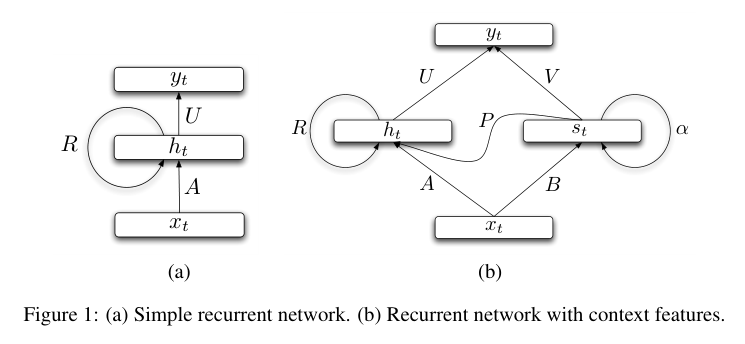
RNN和SCRN的架构图
问题和动机
- 前馈神经网络中的时滞神经网络2,通过一个固定长度的最近历史窗口的结构,达到了能够建模序列数据的目的。但也有以下缺点
- 固定长度的窗口难以学习到长距离依赖
- 只能接受线性增长的参数代价
- 简单的递归神经网络(SRN)由于梯度消失问题同样难以学习到长距离依赖
- 部分非线性激活函数,例如sigmoid使得任何地方的梯度都接近零。(可以通过使用ReLu等激活函数来部分解决这个问题)
- BPTT算法出现矩阵连乘现象,如果矩阵特征值很小(小于1),梯度会迅速收敛到0。
- 过去的带有语境特征(contextual feature)的SRU使用NLP的预训练技术将其引入,并没有将其作为循环网络的一部分来训练
- 本文提出一种较为简单,将语境特征作为模型的一部分来训练的模型
过去的解决方法
- 用Hessian-Free来代替SGD
- LSTM模型
- 用语境特征(contextual feature)进行预训练来引入长距离的上下文信息
Idea
- (trick)使用分层softmax函数来代替原本的softmax函数,因为计算softmax函数的normalization项通常是性能瓶颈(会损失表现性能)
- 使用梯度重归一来避免梯度爆炸(相当于梯度裁剪)
- 非线性激活会导致梯度消失,完全连接的隐藏层在每个时间步都会完全改变状态(参数矩阵完全改变),因此增加一个参数矩阵为单位矩阵,且没有非线性激活的隐藏层。如下式所示 $$s_t = s_{t-1}+Bx_t$$
- 最后的模型如下所示
$$
\begin{aligned}
s_t &= (1-\alpha)Bx_t + \alpha s_{t-1}
\\
h_t &= \sigma(Ps_t+Ax_t+Rh_{t-1})
\\
y_t &= f(Uh_t+Vs_t)
\end{aligned}
$$
- 上述公式固定了$\alpha$,因此只能学习固定的时间尺度。如果将其设为可训练的话,那么就能从不同的时间延迟上学习。如下所示
$$
\begin{aligned}
s_t &= (I-Q)Bx_t + Q s_{t-1}
\\
h_t &= \sigma(Ps_t+Ax_t+Rh_{t-1})
\\
y_t &= f(Uh_t+Vs_t)
\\
diag(Q) &= \sigma(\beta)
\end{aligned}
$$
* 其中Q是对角矩阵,约束对角线元素为对参数向量β做sigmoid变换。这种约束可以使得对角权重保持在0和1之间
论文作者提到,只要还使用标准隐藏层,固定$\alpha$与将其作为可训练的参数区别不大。
实验
实现中将$\alpha$固定为0.95,BPTT的步数为50,普通SRN步数为10。每向前进行5步就进行一次梯度下降,batchsize设为32,初始学习率为0.05,当验证误差不再减少时,每次训练完成后,将学习率除以1.5。
Penn Treebank Corpus数据集
固定$\alpha$参数
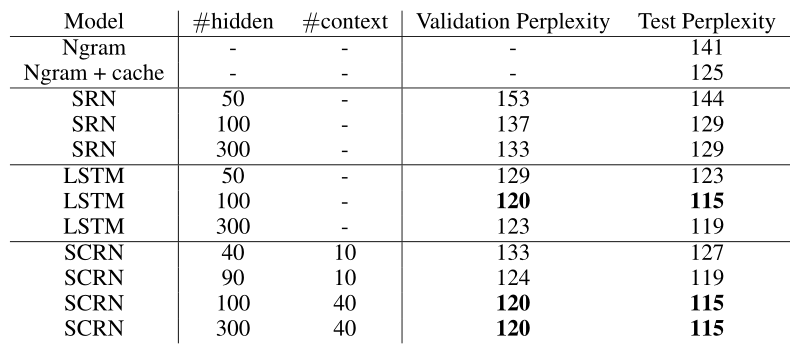
在参数较少的小数据集上,SCRN和LSTM具有相当的性能,当LSTM具有更多的模型参数,大约是4倍。与"leaky neurons"相比,SCRN也有较大改善。结果如下图所示
学习自适应权重
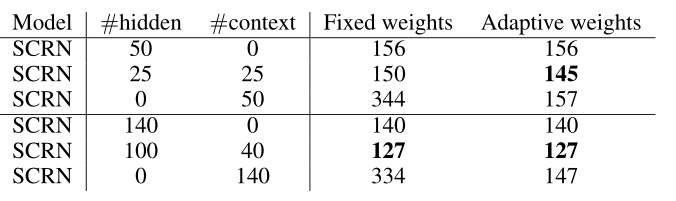
当隐藏层的参数大小很小时,学习自适应权重是有效的,但当参数规模逐渐变大的时候,并没有带来显著的改善。结果如下图所示
Text8数据集
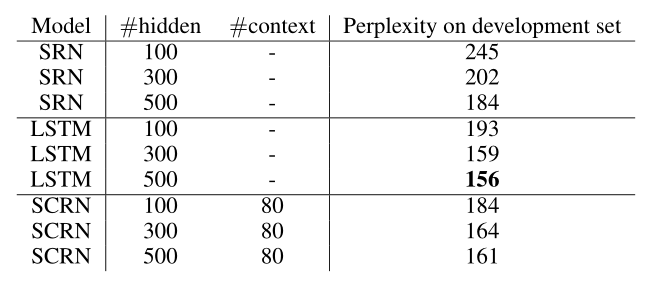
SCRN随着隐藏层和context参数的增加,性能会逐步提升。如下图所示

当参数规模较小时,SCRN优于LSTM,但参数规模变大之后还是LSTM的性能更好,如下图所示
结论
当参数规模受到限制时,SCRN会大大优于LSTM。但当参数规模变大时,有相似的性能。这些所有的模型都不能真正学习到长时记忆。本文还在github上开源了代码3
思考中的问题
- 单位矩阵在模型中起到的作用(推导反向传播)